Introduction
Scikit-learn ek Python library hai jo Machine Learning ke liye use hoti hai. Ye library tumhe ready-made algorithms deti hai jisse tum easily ML models bana sakte ho.
What is it
Python ML library
Built on NumPy, Pandas, SciPy
Simple aur consistent API
Why important
Fast prototyping
Easy to use
Industry me widely used
Real-world usage
Fraud detection
Customer churn prediction
Sales forecasting
Recommendation systems
Basic Concepts
Machine Learning Types
Supervised Learning → labeled data (Regression, Classification)
Unsupervised Learning → no labels (Clustering)
Core Components
Dataset
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target
Train-Test Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Model Training
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
Prediction
y_pred = model.predict(X_test)
Evaluation
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy*100:.2f}%")All Functions and Features
Preprocessing
StandardScaler
StandardScaler data ko normalize karta hai taaki sab features ek hi scale par aa jayein.
Isme mean 0 aur standard deviation 1 ho jata hai, jisse model better aur fair learning karta hai.
Ye mainly distance-based aur regression models me use hota hai.
Before vs After Scaling
Before Scaling (Original Data)
Age Salary
18 20000
25 30000
30 50000
35 80000
40 100000👉 Problem:
Salary ka scale bahut bada hai
Age ka scale chhota hai
After StandardScaler
Age Salary
-1.41 -1.21
-0.70 -0.82
0.00 0.00
0.70 0.82
1.41 1.21
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
Use: Feature scaling ke liye
MinMaxScaler
MinMaxScaler data ko ek fixed range (usually 0–1) me convert karta hai.
Ye minimum value ko 0 aur maximum value ko 1 bana deta hai, baaki values proportion me scale hoti hain.
Isse sab features same range me aa jate hain, jo models ko better learning me help karta hai.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)# Create graphs comparing original, StandardScaler, and MinMaxScaler
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import matplotlib.pyplot as plt
# Original data
data = pd.DataFrame({
'Age': [18, 25, 30, 35, 40],
'Salary': [20000, 30000, 50000, 80000, 100000]
})
# StandardScaler
std_scaler = StandardScaler()
std_scaled = std_scaler.fit_transform(data)
std_df = pd.DataFrame(std_scaled, columns=data.columns)
# MinMaxScaler
mm_scaler = MinMaxScaler()
mm_scaled = mm_scaler.fit_transform(data)
mm_df = pd.DataFrame(mm_scaled, columns=data.columns)
# Plot Original Data
# plt.scatter(data['Age'], data['Salary'])
# plt.xlabel('Age')
# plt.ylabel('Salary')
# plt.title('Age vs Salary')
# plt.show()
# # Plot Standard Scaled
# plt.scatter(std_df['Age'], std_df['Salary'])
# plt.xlabel('Age')
# plt.ylabel('Salary')
# plt.title('Age vs Salary')
# plt.show()
# # Plot MinMax Scaled
# plt.scatter(mm_df['Age'], mm_df['Salary'])
# plt.xlabel('Age')
# plt.ylabel('Salary')
# plt.title('Age vs Salary')
# plt.show()
# sab grapgh ek sath
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.scatter(data['Age'], data['Salary'])
plt.xlabel('Age')
plt.ylabel('Salary')
plt.title('Original Data')
plt.subplot(1, 3, 2)
plt.scatter(std_df['Age'], std_df['Salary'])
plt.xlabel('Age')
plt.ylabel('Salary')
plt.title('Standard Scaled')
plt.subplot(1, 3, 3)
plt.scatter(mm_df['Age'], mm_df['Salary'])
plt.xlabel('Age')
plt.ylabel('Salary')
plt.title('MinMax Scaled')
plt.tight_layout()
plt.show()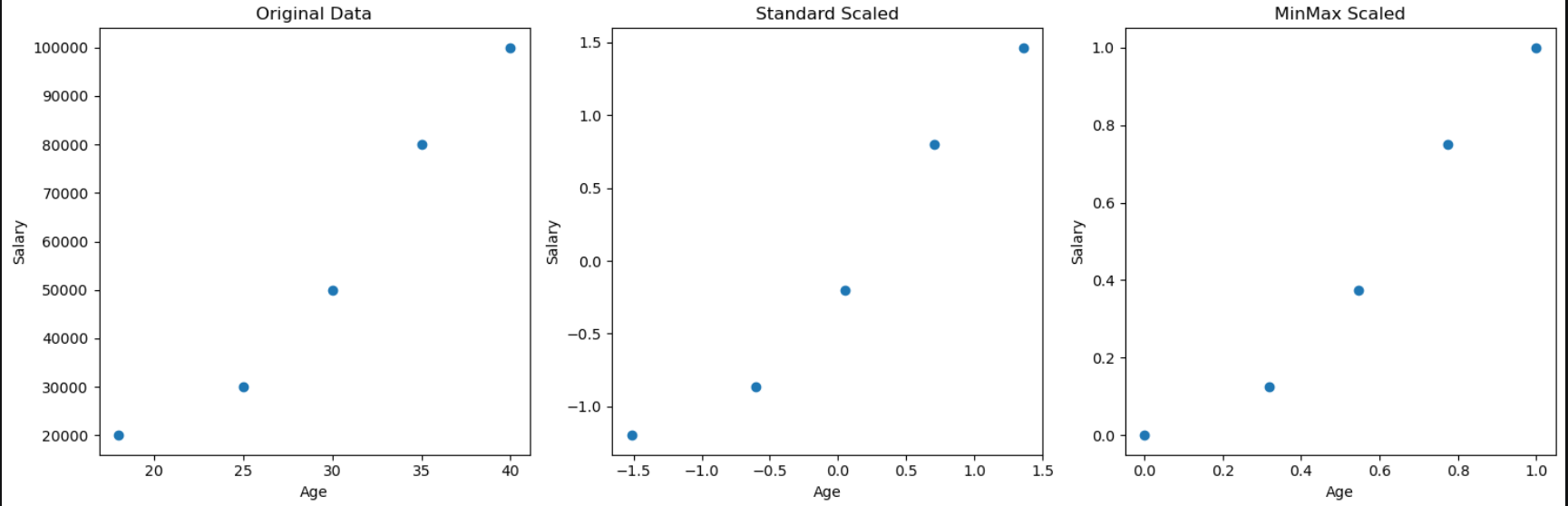
LabelEncoder
y = ['Low', 'Medium', 'High', 'Medium', 'Low']
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_encoded = le.fit_transform(y)
print(y_encoded) # Output: [1 2 0 2 1]
OneHotEncoder
OneHotEncoder categorical values ko binary (0/1) columns me convert karta hai. Har category ke liye alag column banata hai, isliye model ko clear signal milta hai aur koi order create nahi hota.
Example (Before Encoding)
import numpy as np
X = [['Red'], ['Blue'], ['Green'], ['Red']]
X = np.array(X)
type(X)
X
# output
# <class 'numpy.ndarray'>
# array([['Red'],
# ['Blue'],
# ['Green'],
# ['Red']], dtype='<U5')
Model text directly samajh nahi sakta, isliye encoding karna zaroori hai.
X = [['Red'], ['Blue'], ['Green'], ['Red']]
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(handle_unknown='ignore')
X_encoded = encoder.fit_transform(X)
print(X_encoded.toarray())
#df = pd.DataFrame(X_encoded.toarray(), columns=encoder.get_feature_names_out())
#dfAfter Encoding
x0_Blue x0_Green x0_Red
0 0.0 0.0 1.0
1 1.0 0.0 0.0
2 0.0 1.0 0.0
3 0.0 0.0 1.0Yaha har color ek alag column ban gaya aur values 0/1 me aa gayi.
handle_unknown='ignore' ka matlab hai agar test data me koi new category aaye (jaise 'Yellow'), to error nahi aayega, bas us row me sab values 0 ho jayengi.
OneHotEncoder ka use tab karte hain jab data me koi natural order na ho (jaise color, city, category).
Ek line me samajh lo: OneHotEncoder categorical data ko multiple binary columns me convert karta hai bina kisi order ke, jisse model better learn karta hai.
SimpleImputer
SimpleImputer ka use missing values (NaN) ko fill karne ke liye hota hai.
Yaha strategy='mean' ka matlab hai har column ke missing values ko us column ke average (mean) se replace karna.
Example samjho:
import numpy as np
X = [
[10],
[20],
[np.nan],
[30]
]
Yaha ek value missing hai (NaN)
Code:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
X_filled = imputer.fit_transform(X)
print(X_filled)
Output:
[[10.]
[20.]
[20.]
[30.]]
Samajh kya aaya:
Mean = (10 + 20 + 30) / 3 = 20
Missing value ko 20 se replace kar diya
Important baatein:
fit()mean calculate karta haitransform()missing values fill karta haifit_transform()dono ek saath karta hai
Kab use kare:
Jab data me missing values ho
Numeric columns ke liye (mean, median use hota hai)
Ek line me samajh lo:
SimpleImputer missing values ko kisi rule (jaise mean) se fill karta hai taaki model data properly use kar sake.
Models
1. Regression (Continuous Output)
👉 Jab output number hota hai (price, salary, marks)
Example:
House price predict karna
Salary estimate karna
Code:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
👉 Ye input aur output ke beech straight line relation find karta hai
2. Classification (Categories)
👉 Jab output category hota hai (Yes/No, 0/1)
Example:
Spam vs Not Spam
Disease hai ya nahi
Decision Tree Classifier
👉 Tree structure me decision leta hai (if-else logic)
Code:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
👉 Easy to understand, but overfitting ho sakta hai
Random Forest Classifier
👉 Multiple decision trees ka group (ensemble)
Code:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
👉 Zyada accurate aur stable
👉 Overfitting kam hota hai
3. Clustering (Unsupervised Learning)
👉 Jab data me labels nahi hote
Example:
Customers ko group karna
Similar users identify karna
KMeans
👉 Data ko K groups (clusters) me divide karta hai
Code:
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3)
model.fit(X)
labels = model.predict(X)
👉 Similar data ek cluster me aa jata hai
Final Summary (1 line each)
👉 LinearRegression → number predict karta hai
👉 DecisionTree → rules se classify karta hai
👉 RandomForest → multiple trees se better prediction
👉 KMeans → similar data ko group karta hai
Pipeline
Pipeline ko ek real example se samajhte hain — step by step, jaise tum project me karoge
Maan lo tumhare paas data hai jisme Age aur Salary se predict karna hai ki user product buy karega ya nahi.
Example data:
import pandas as pd
data = pd.DataFrame({
'Age': [18, 25, 30, 35, 40],
'Salary': [20000, 30000, 50000, 80000, 100000],
'Buy': [0, 0, 1, 1, 1]
})
X = data[['Age', 'Salary']]
y = data['Buy']
Ab normally tum kya karte:
Pehle scaling
Fir model training
But Pipeline ye sab automatically karega.
Pipeline banate hain:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
Ab training aur prediction:
pipeline.fit(X, y)
y_pred = pipeline.predict(X)
print(y_pred)
Samajh kya hua:
Step 1: StandardScaler ne Age aur Salary ko scale kiya
Step 2: LogisticRegression ne model train kiya
Step 3: Predict karte time bhi same scaling automatically apply hui
Tumhe manually scaling likhne ki zarurat nahi padi.
Agar bina pipeline karte to ye sab likhna padta:
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression()
model.fit(X_scaled, y)
y_pred = model.predict(X_scaled)
Difference dekho:
Pipeline → clean, safe, production ready
Manual → repetitive, error-prone
Real samajh:
Pipeline ek fixed machine hai jisme data daalo aur output mil jata hai, beech ke saare steps automatically handle ho jate hain.
Intermediate Usage
Combining Steps
pipeline = Pipeline([
('imputer', SimpleImputer()),
('scaler', StandardScaler()),
('model', RandomForestClassifier())
])
Feature Selection
SelectKBest data me se sabse useful K features choose karta hai taaki model better aur fast kaam kare
from sklearn.feature_selection import SelectKBest
selector = SelectKBest(k=5)
X_new = selector.fit_transform(X, y)
Advanced Concepts
Hyperparameter Tuning
GridSearchCV multiple hyperparameter combinations try karke best model automatically select karta hai
from sklearn.model_selection import GridSearchCV
params = {'n_estimators': [50,100], 'max_depth': [3,5,10]}
grid = GridSearchCV(RandomForestClassifier(), params)
grid.fit(X_train, y_train)
Cross Validation
Cross Validation model ko multiple splits par test karke uski real aur reliable performance batata hai
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)Interview Questions
Basic
Scikit-learn kya hai
fit vs transform
Intermediate
Pipeline kya hota hai
Cross-validation ka use
Advanced
GridSearch kaise kaam karta hai
Overfitting kaise avoid karte ho
Scenario
Dataset me missing values hai:
Imputer use
Pipeline build
Conclusion
Key Learnings
Scikit-learn ek complete ML toolkit hai
Pipeline most important concept hai
Evaluation critical hai
When to Use
Structured data
Fast ML models
Production pipelines
Final Advice
Practice karo
Real datasets use karo
End-to-end ML projects banao